Pada penghujung bulan April 2026, syarikat pembangun perkhidmatan AI DeepSeek telah memperkenalkan model bahasaraya terbaru mereka, iaitu DeepSeek v4, menawarkan konteks sehingga 1 juta token, membolehkan ia kekal konsisten dalam penjanaan, dan sesuai untuk pembangunan kod atau dokumen yang besar.
Terkini, sebagai kemas kini kepada model bahasa raya (LLM) tersebut, DeepSeek telah memperkenalkan teknologi AI baru yang dinamakan DSpark, yang merupakan rangka kerja speculative decoding yang dimanfaatkan oleh pusat data DeepSeek untuk mempercepatkan proses inferens dan menghasilkan jawapan untuk pengguna pada kadar yang lebih pantas, di samping mengurangkan penggunaan tenaga elektrik yang diperlukan untuk soalan dan permintaan yang secara lazimnya akan memerlukan jumlah token yang banyak.

Dengan rangka kerja DSpark, DeepSeek boleh mengurangkan jumlah token yang diperlukan untuk permintaan yang diajukan oleh pengguna, khususnya apabila permintaan dan output memerlukan jumlah token yang banyak. DeepSeek mengatakan bahawa dengan bantuan DSpark, DeepSeek v4 boleh melalui proses inferens dan menghasilkan output pada kadar 60-85% lebih pantas berbanding sebelum ini.
Penerangan ringkas tentang bagaimana DeepSeek melakukan perkara ini ialah dengan menggunakan model draf yang ringan untuk mencadangkan respons dan kemudian mengesahkannya secara berkelompok menggunakan LLM yang lebih besar untuk mendapatkan output yang lebih pantas tetapi masih tepat.
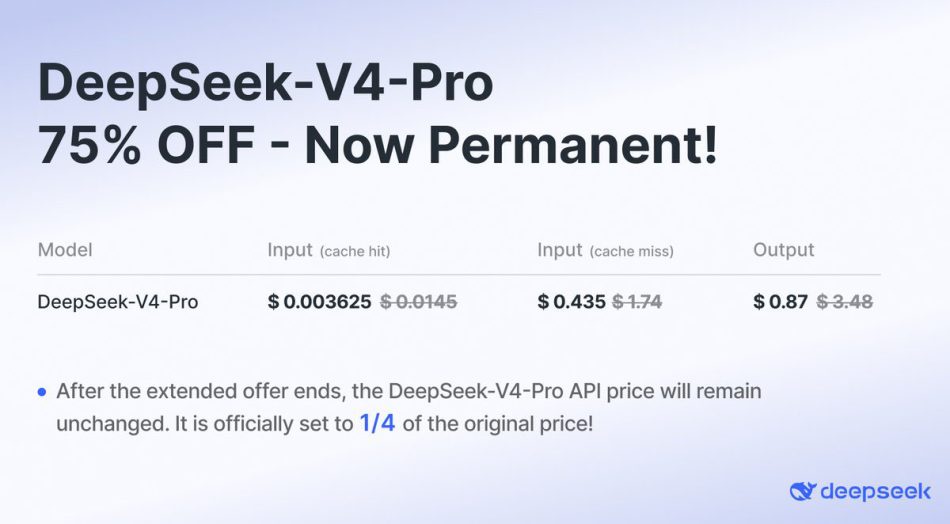
Penerangan yang lebih mendalam tentang bagaimanakah DSpark berfungsi dapat dibaca melalui artikel ini, dan ia menjawab bagaimanakah DeepSeek baru-baru ini boleh menurunkan harga langganan DeepSeek v4 Pro mereka apabila perkhidmatan AI lain seperti ChatGPT oleh OpenAI dan Claude oleh Anthropic meningkatkan harga langganan mereka.
Sumber: Medium